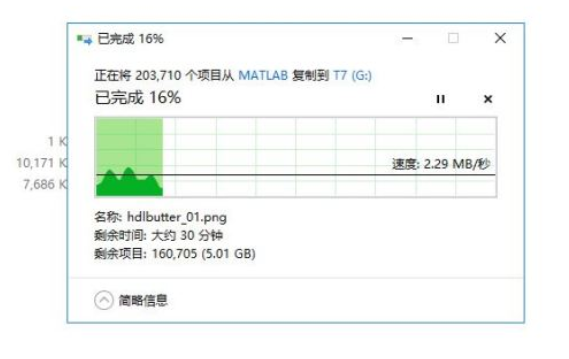
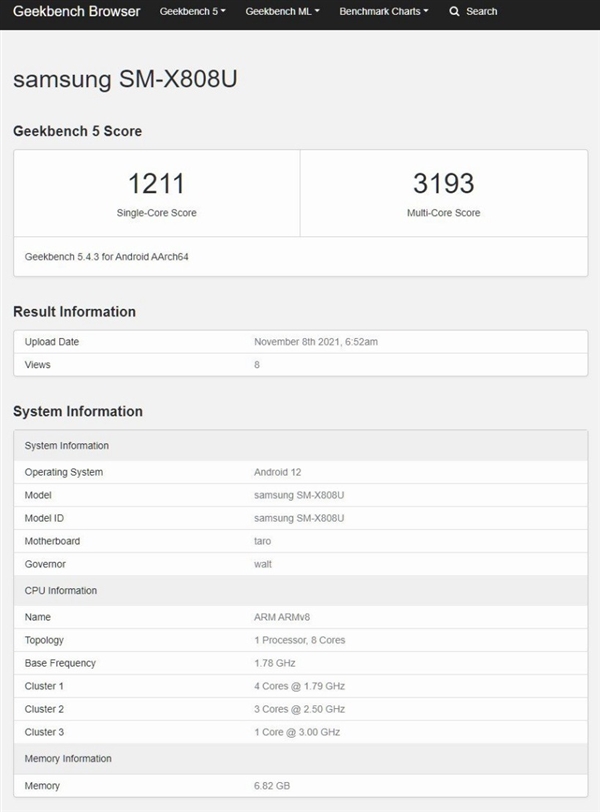
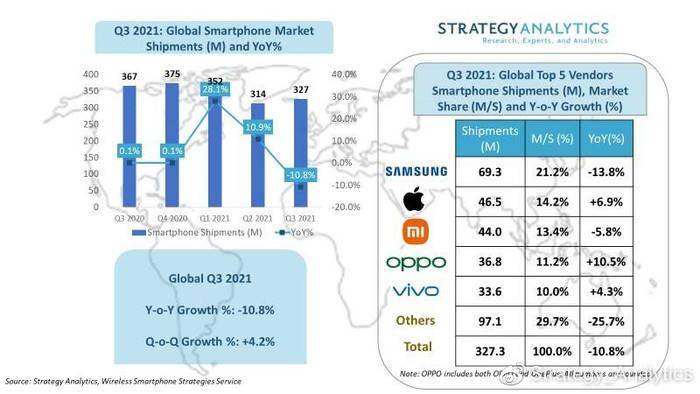
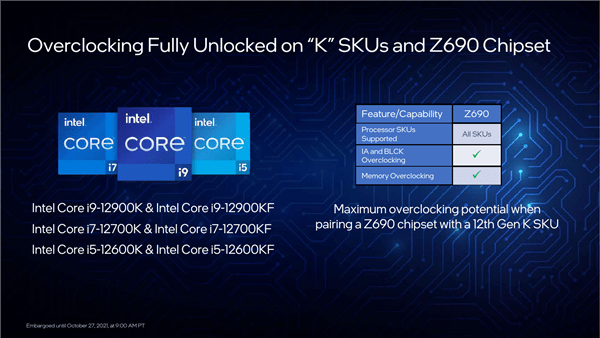
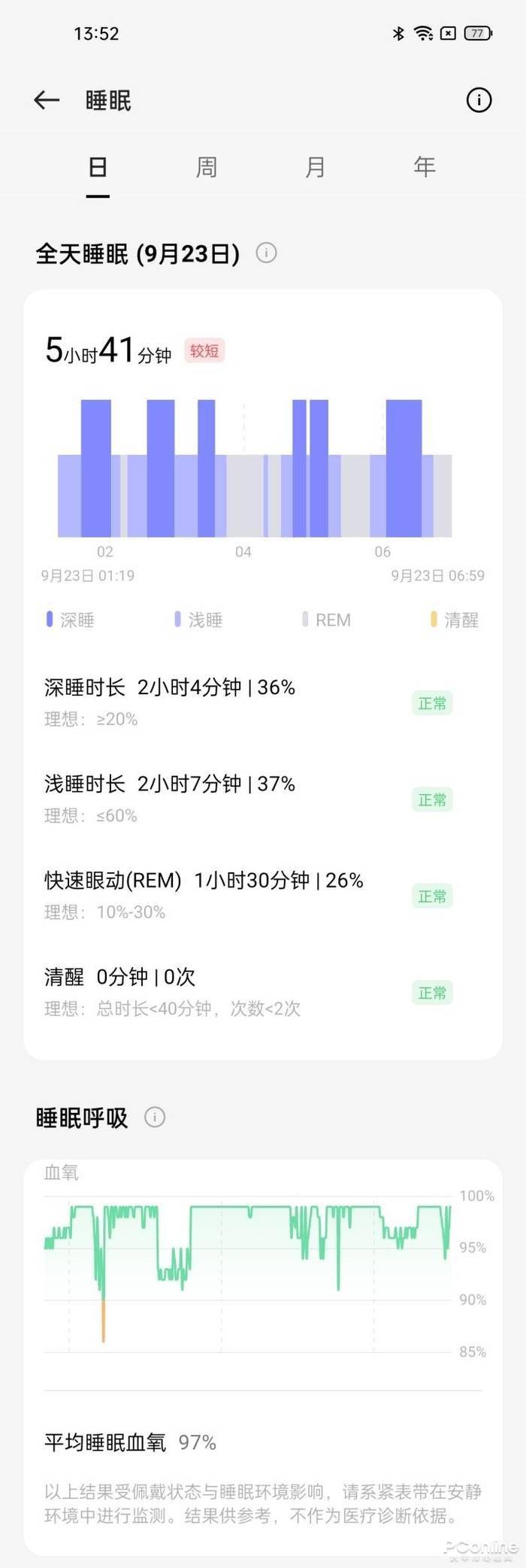
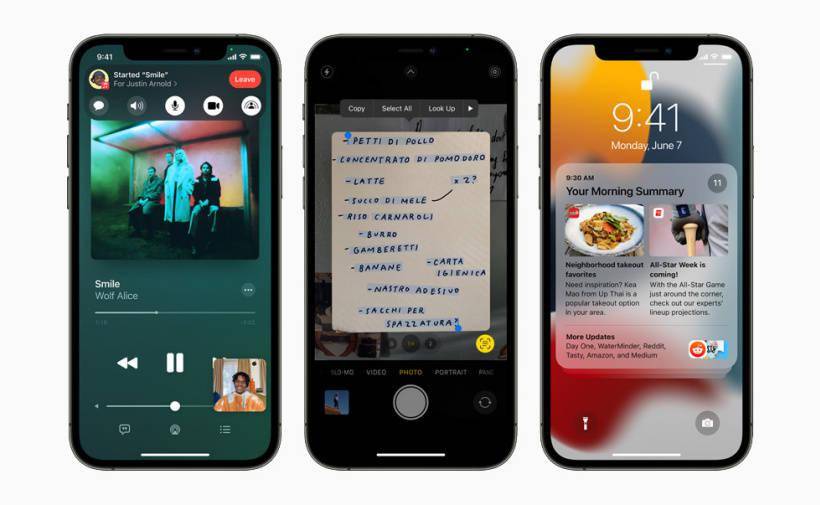
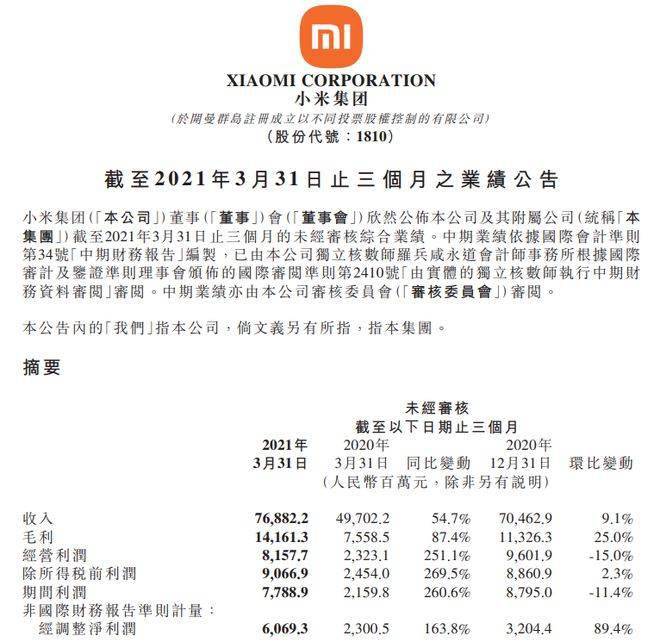
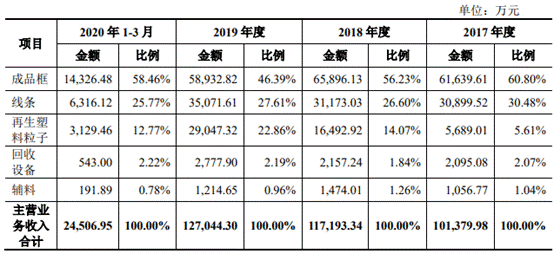
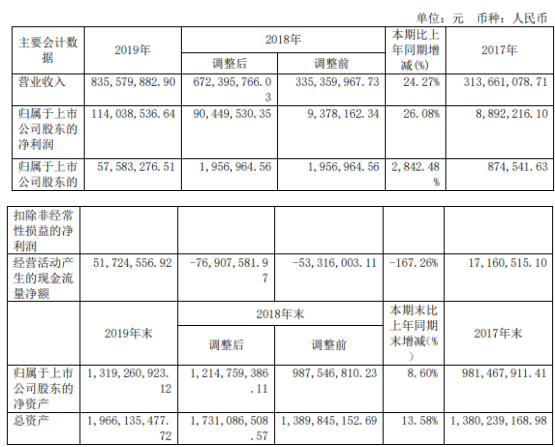
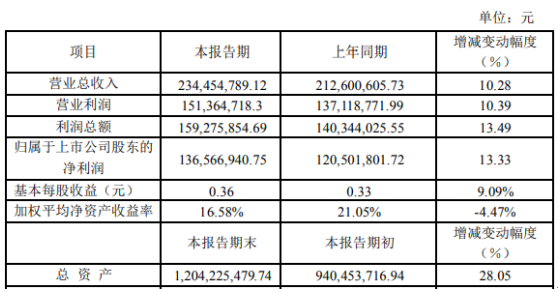
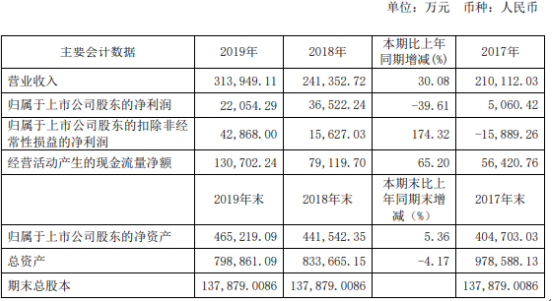
为了冲击百亿亿次计算,美国官方准备了三套不同系统,分别由Intel、AMD、AMD+NVIDIA联合打造。现在看起来,AMD+NVIDIA的联合方案进展最快。这套名为“Polaris”(北极星)的超算,隶属于美国能源部阿贡国家实验室ALCF(阿贡领先计算设施),主要为用户的算法和科学领域的超级规模的研究和探索提供支持,并对学术界、政府机构、行业研究人员开放使用。
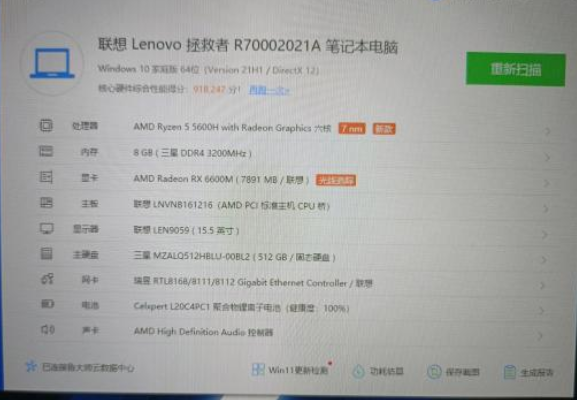
它基于Cray Slingshot 10高性能可扩展互连架构,惠与(HPE)负责建造,共有560个节点,每个节点配备两颗AMD EPYC 7532处理器、四块NVIDIA A100计算卡,合计1120颗处理器、2240块计算卡。
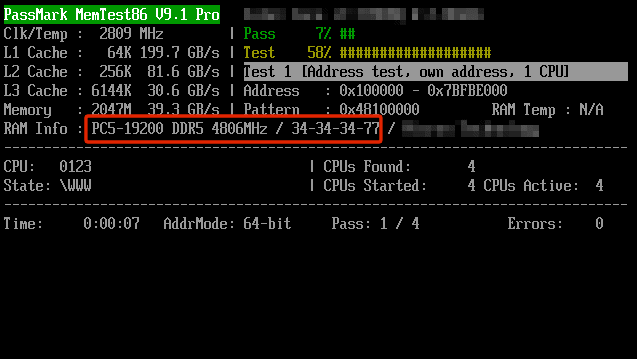
EPYC 7532拥有32核心64线程(Zen2机构),A100计算卡则有6912个CUDA核心(Ampere架构),因此这套超算总共有多达35840个CPU核心、15482880个GPU核心,只是不知道A100这里的显存是40GB还是80GB。
整套系统的FP64双精度浮点峰值性能将达44PFlops(44千万亿次每秒),在当今全球超算TOP500榜单上可以排在第十位。
不过,它的理论AI性能可以高达惊人的1.4EFlops(140亿亿次每秒),通过处理数据密集型和AI高性能计算工作负载,将模拟和机器学习相结合。
Polaris超算将在今年年内上线,明年3月份升级为Slingshot 11架构,处理器更换为Zen3架构的EPYC 7543,仍是32核心,但性能将再上一个台阶。
AMD为美国能源部橡树岭国家实验室(ORNL)打造的百亿亿次超算名为“Frontier”,配备Zen4架构下代EPYC处理器、Instinct计算卡,合同价值6亿美元。
Intel中标的超算名为“Aurora”,基于其下代Sapphire Rapids至强处理器、Xe HPC Ponte Vecchio计算卡。
不过,AMD、Intel的新平台都尚未发布,大部分都要到明年才会完成,超算系统也顺应延期,预计会在2022-2023年才会陆续上线。